

十年老项目的生存报告
东八区北京时间 2025 年 7 月 13 日 —— 当我们打开一台运行了十年的服务器,就像打开了一个技术考古现场。本文将带你复盘一个十年前上线的项目如何活到今天,以及那些年学长/学姐亲手埋下的"技术债地雷"。
技术栈分析
十年前,那时候搭建网站还没有那么多框架可言,最简单的方法使用php进行一个echo,网页就做好了。学长/学姐那时候也没使用什么框架,还是前后端不分离的设计,导致很多py文件就直直的躺在根目录下。前端使用的是jQuery + Bootstrap3,后端使用的是Python2 + Flask,数据库使用的是Sqlite。
前端的代码长这样:
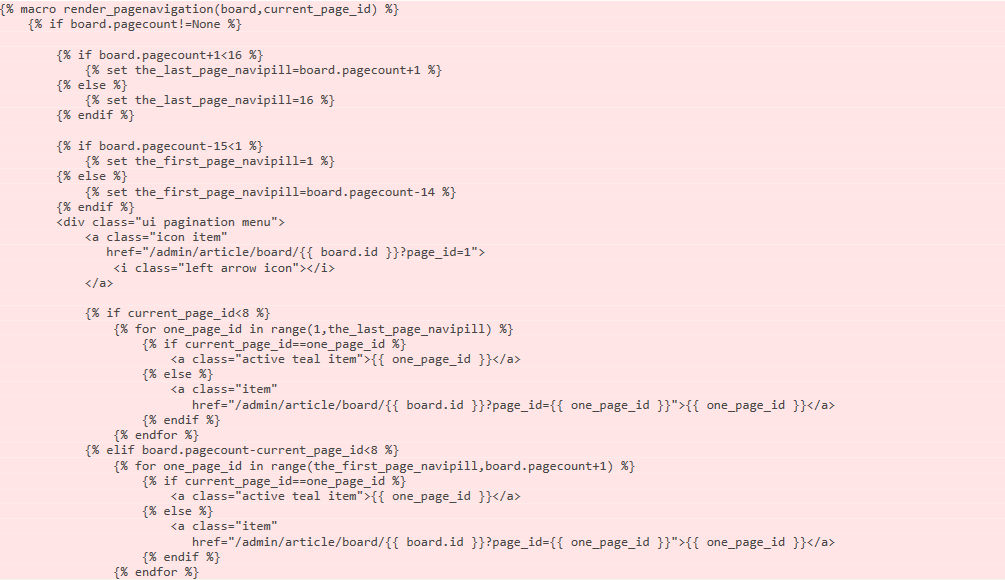
后端的代码长这样:
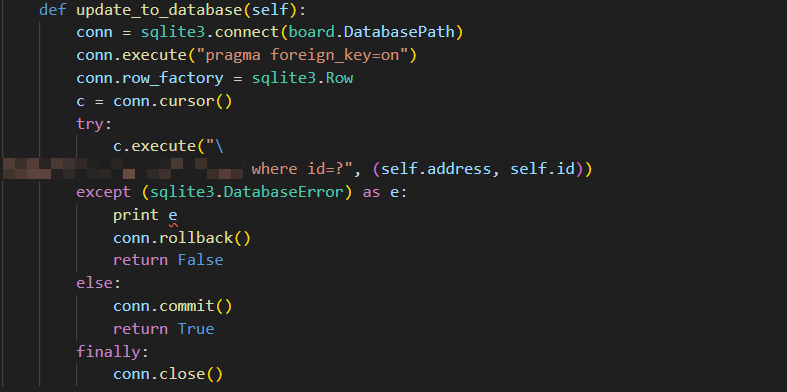
是不是很像大家的课设作业呢😂。
当时可能没有现在那么多的面板可以选择,也没有docker之类的容器化部署,学长/学姐又是如何部署的呢?又如何保证这个项目能运行十年的呢?
通过对进程进行分析,可以发现使用的是supervisord,保证后端的正常运行,至于具体的配置,看起来应该是复制的example然后手搓的。(图中的docker是我后面装的。)
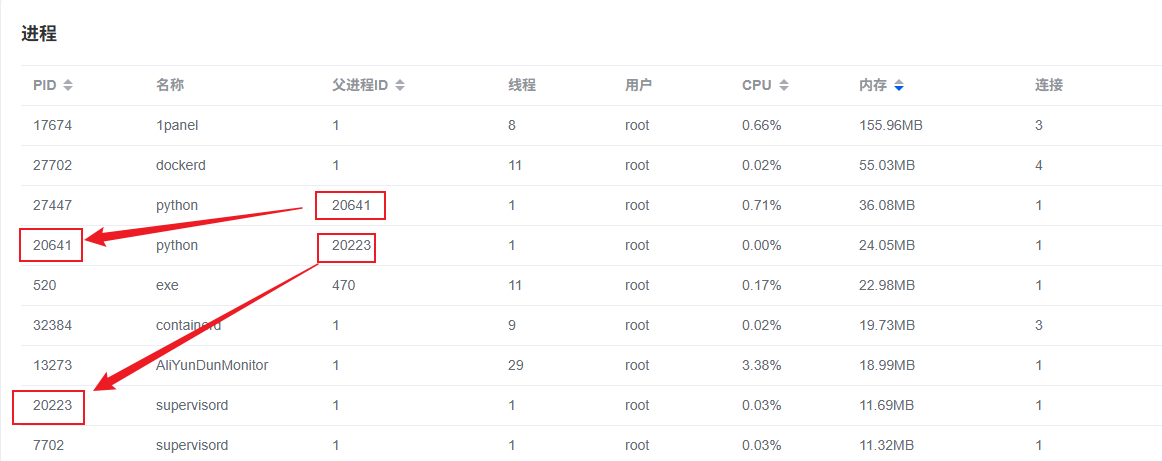
至于nginx,也是下载的1.12.1,放在/usr/local目录下,配置也是手搓的,不过js、css文件没有通过flask进行代理是好评的。
至于数据备份,采用的就是非常简单直白的crontab每周进行cp数据库文件,然后每月固定时间进行压缩,保存到另一个文件夹,再每年压缩备份到另一个文件夹。

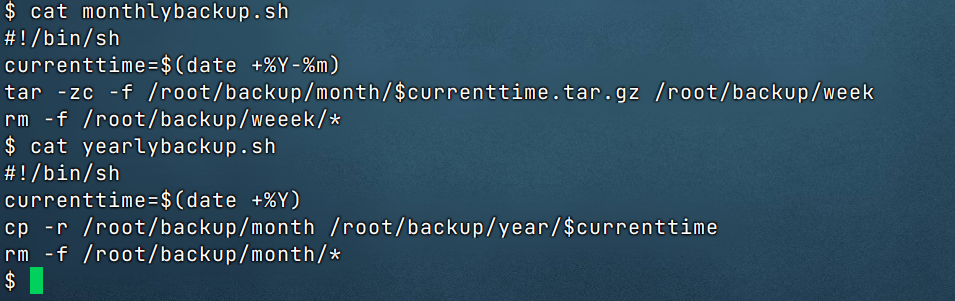
发现什么问题了吗?首先,没有对代码进行备份,其次,没有对上传的文件的进行备份。最后,当备份失败时,没有任何提醒,这是十分忌讳的,使用备份不就是为了数据安全吗,备份失败没有提示,到时候数据是找不回的。
运行十年真的不出问题吗?(运维篇)
硬盘炸了
那当然不是了,关于这台服务器处理最多的问题,就是硬盘爆炸了。
为什么硬盘会炸呢?
首当其冲的是高达20G的备份文件(已转移到OSS):

紧接着是高达5G的Nginx log:
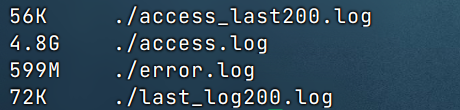
最后,不乏每届运维人员,拉了不擦屁股的💩。

这还会导致其他问题吗?那是当然,有几个月的数据库因为硬盘没有剩余空间而备份失败了。。。其中也不乏部分月份备份是不全的。
内存泄露
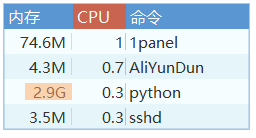
当时一看一个web程序占用了2.9G内存吓了一跳,你以为这就结束了吗?
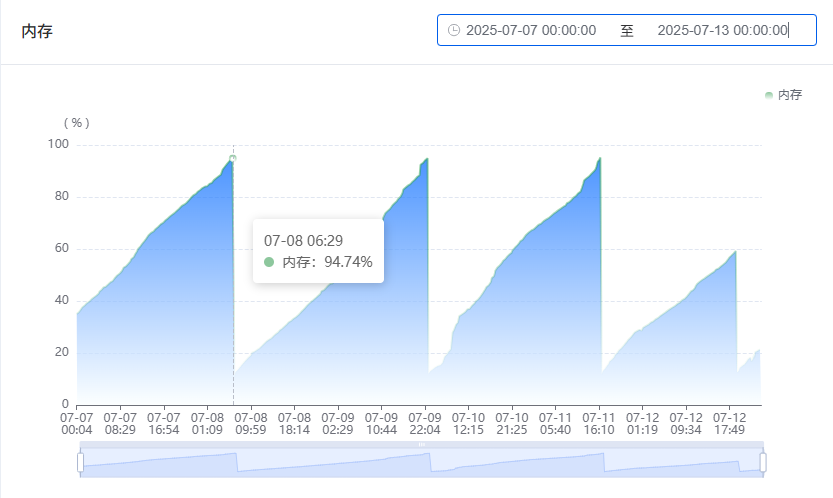
通过运维面板的统计数据可以看到,最高达到了3.7G。
运行十年真的不出问题吗?(代码篇)
到底是about还是abort呢?
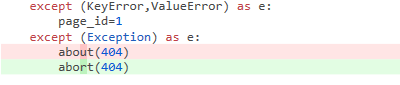
close还是不close?

分页先取出来再pop
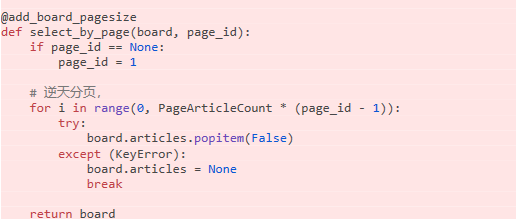
当然这些只是比较明显的问题,还有很多不明显的问题。
如何解决?
硬盘炸了
对于阿里云带宽只有5M的小鸡,如果把20G的备份下载下来,需要 20 * 1024 * 8 / 5 = 32768 s ≈ 9h,连续占满9个小时带宽,是非常影响用户体验的。如果能走阿里内网上那肯定是非常不错的,于是想到了阿里云的OSS。40G只要9块钱一年,也是非常划算的。
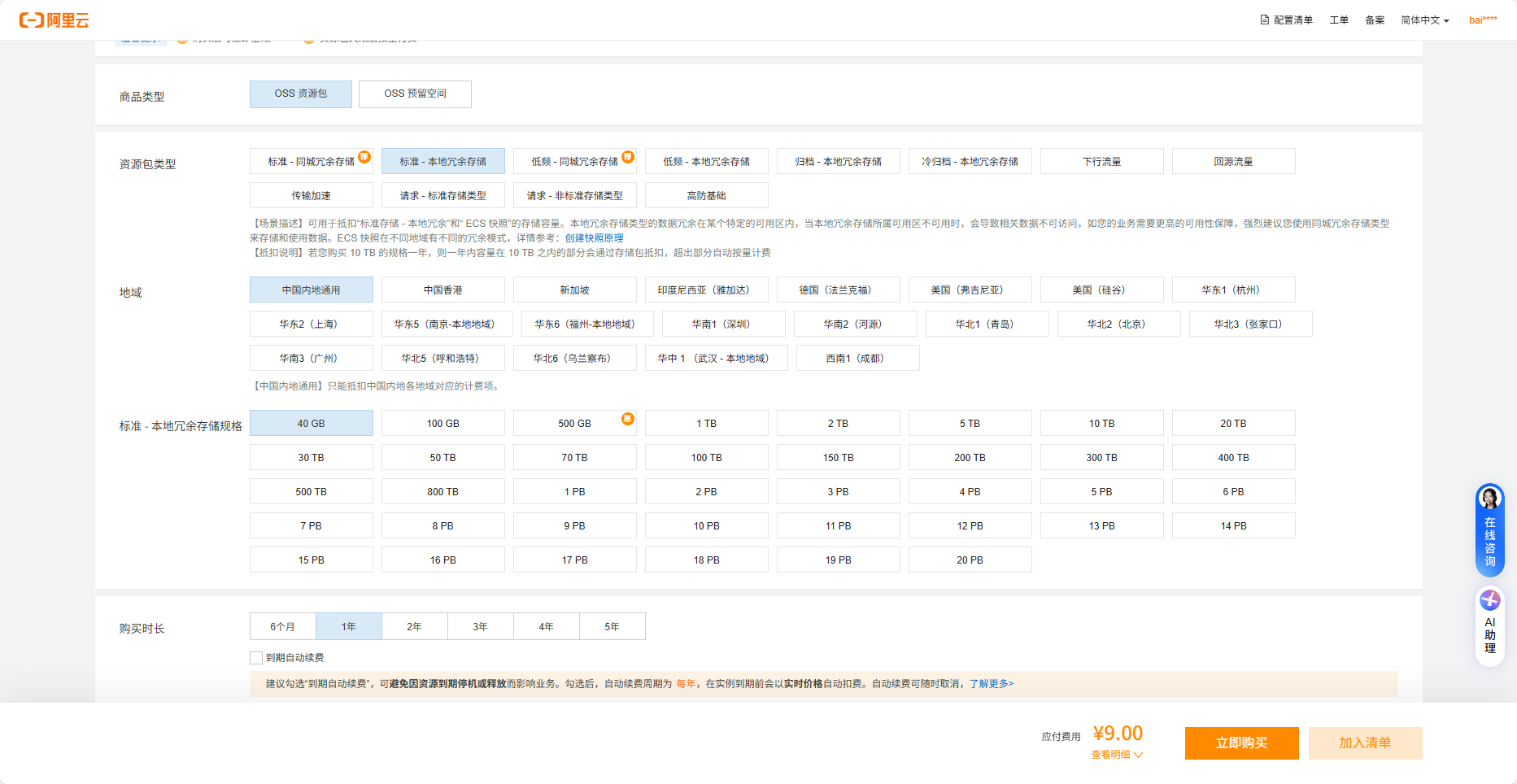
如何上传呢?开始试图通过1Panel的备份目录功能进行上传,使用的时候发现1Panel需要将文件打包成压缩包才能上传,这哪还有剩余空间。于是找是否有命令行的方式,最后找到了阿里云自己的ossutil工具,可以通过cp命令备份到oss上。
这里也吐槽一下阿里云的文档,非常地难找,并且在控制台创建接入点之后,居然是没用的,得使用提供的公共云接入点。
当然,最后还得把原来的备份策略给换了。
内存泄露
看到这里,想到是什么原因了吗?对,就是数据库连接没有正确关闭,学长/学姐在页脚信息获取的时候,忘记对connection进行close了,而这又是一个高频被调用的函数,每调用一次,就会增加一点内存。
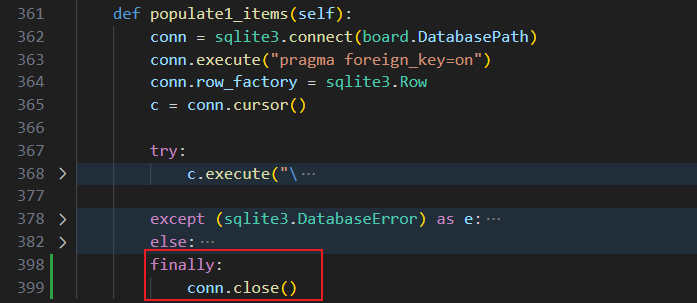
那为什么还能稳定运行呢?哈哈,通过日志可以看到,程序每天都会因为OOM而被杀掉一次,但是又被supervisord重启了。

总结
对于学长/学姐十年前的项目,有这么多问题情有可原,当时技术并没有那么成熟,相关资料也少之又少,能够完成已经非常不错了。但是我们也应该通过学长/学姐踩过的坑中学习,以后避免出现类似的情况。