

深度学习第二周总结
这几周事情太多了!!
先把博客写了,等有空的时候再回来完善。
一、学习总结
二、实验结果
1. CNN 与全连接网络分别对 MNIST 数据集分类
(1) MNIST 数据集下载
利用 Pytorch 自带的数据集加载器下载 MNIST 数据集并存放在 ./data 文件夹
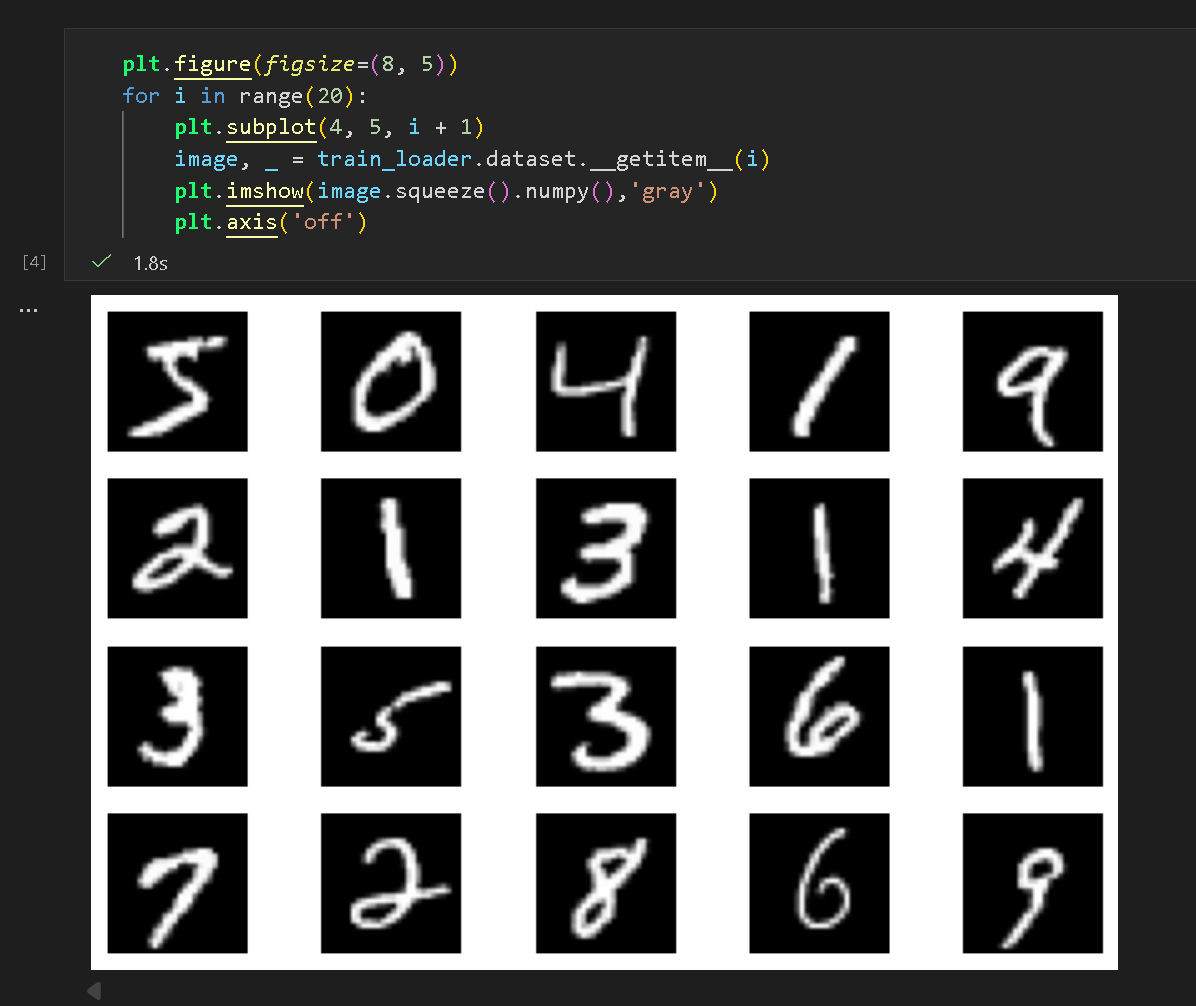
(2) 展示部分手写数字数据
使用 matplotlib 对部分数据进行输出展示
(3) 封装全连接层与 CNN 层
继承 torch.nn 后分别实现构造函数和 forward 前向传播函数,
利用 autograd 自动实现反向传播。
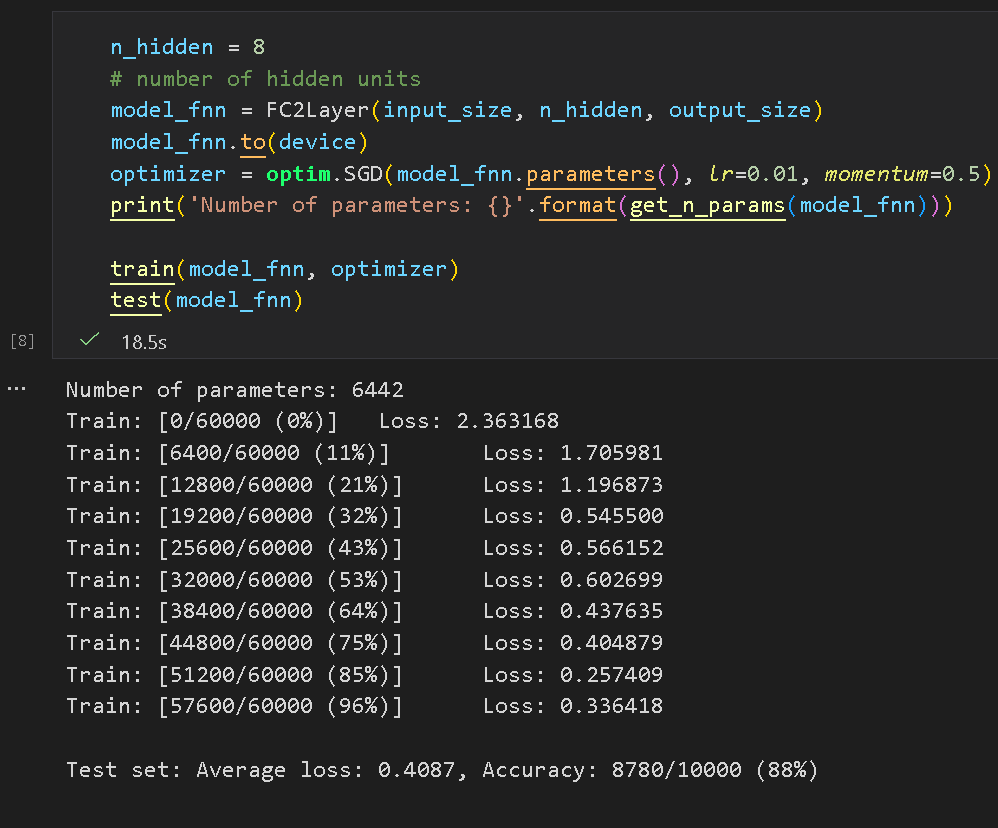
(4) 测试网络分类效果
普通全连接网络达到了 88% 的准确率:
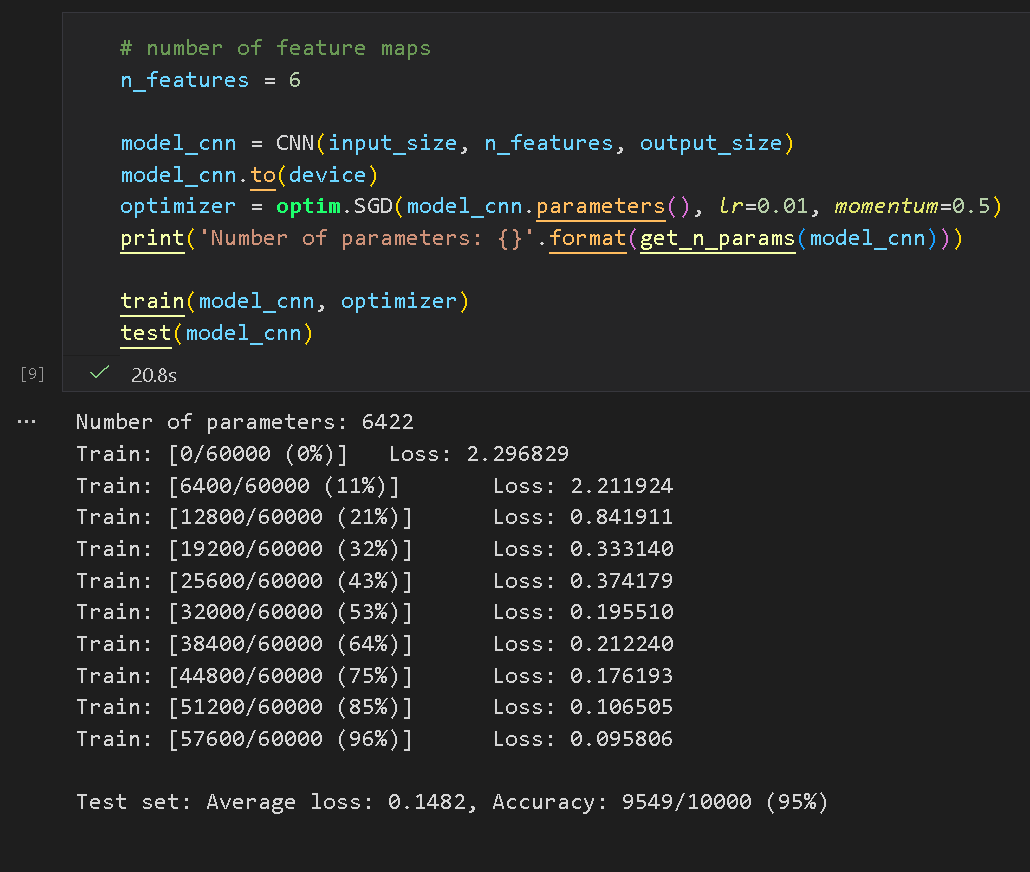
CNN 达到了 95% 的准确率,具有显著优势:
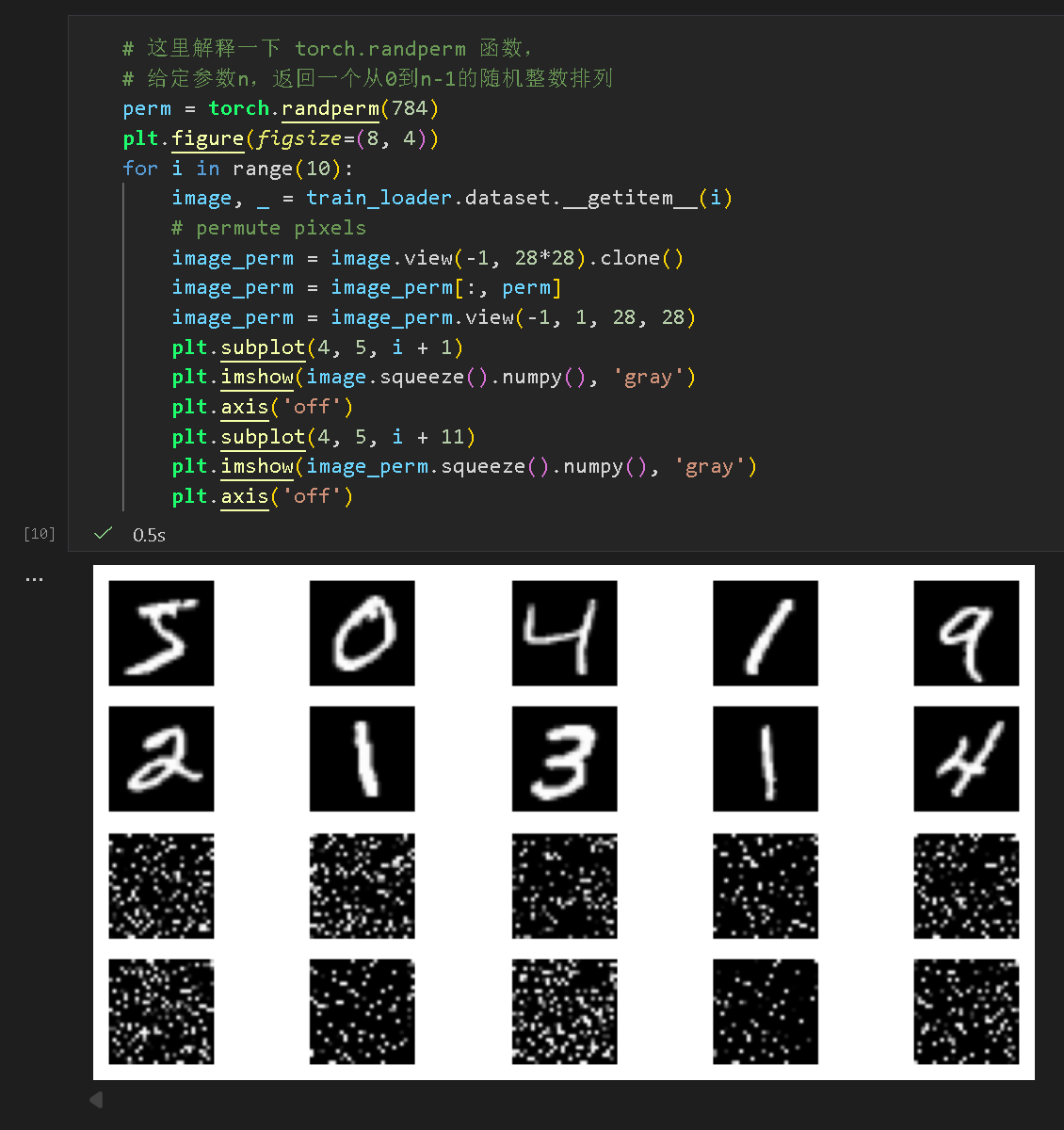
(5) 数据打乱进行对照实验
利用 shuffle 打乱数据集:
再次使用全连接网络:
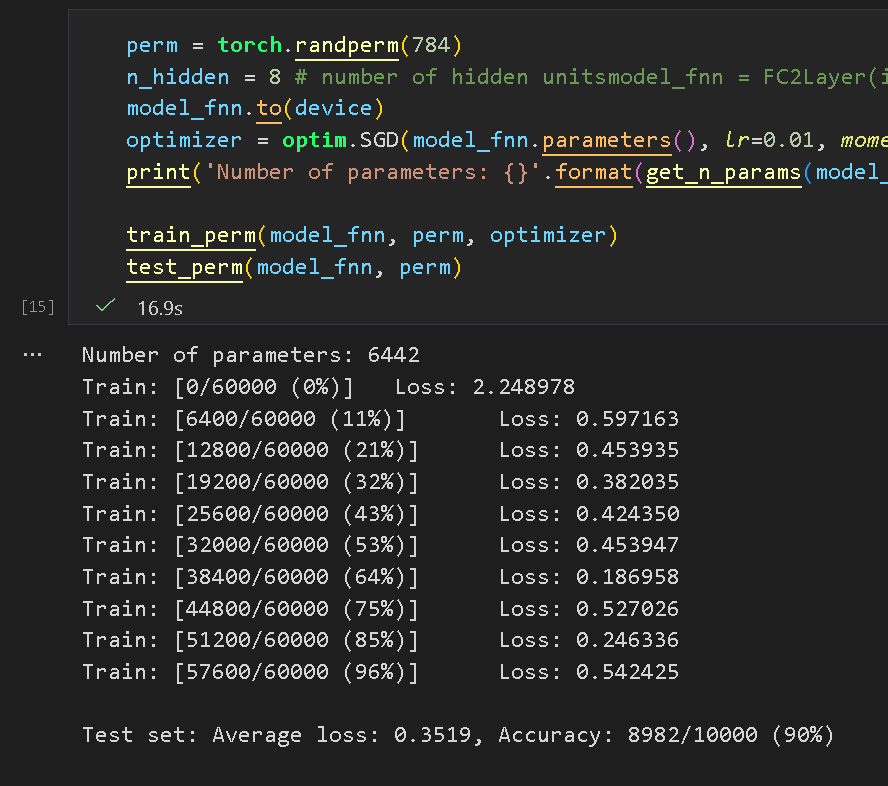
再次使用 CNN:
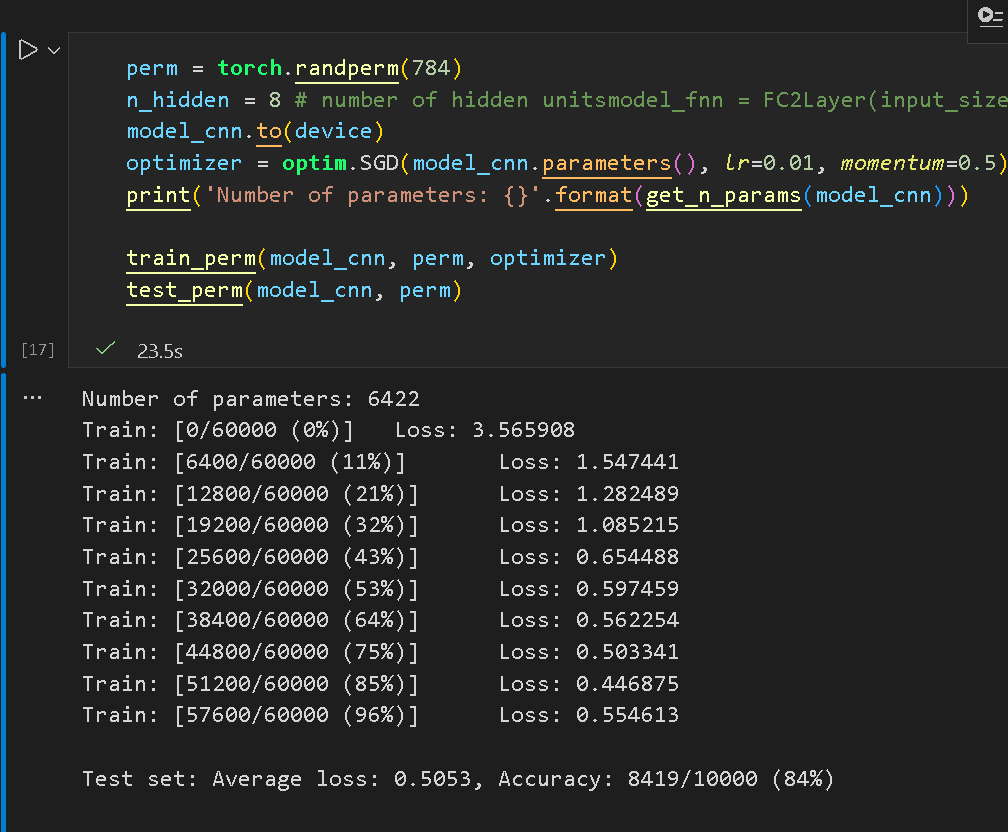
三、问题总结
1. dataloader 里面 shuffle 取不同值有什么区别?
在 shuffle = True 时,每个 epoch 开始前随机打乱样本顺序。这能放置数据顺序在模型训练过程中产生干扰,提高收敛稳定性,降低过拟合风险;在 shuffle = False 时,数据顺序是固定的,使得结果可以复现,便于验证。
2. transform 里,取了不同值,这个有什么区别?
transform 对原始数据进行变换处理,能够对不同特征的数据进行表达力上的增强,通过特定的变换方式使得模型具有更高的泛用性,并暗示了模型可以忽略哪些特征进行泛化训练。
3. epoch 和 batch 的区别?
epoch 指的是训练批次,而 batch 指的是每一次训练中使用的样本数。epoch 决定了训练次数多少,而 batch 影响着显存占用、梯度噪声等。
4. 1x1 的卷积和 FC 有什么区别?主要起什么作⽤?
FC 输入整个特征图,并输出一个向量;1x1 的卷积对每个位置的向量做相同的线性变换,以同一套权重对每个位置进行变换。1x1 卷积避免了数据权重与位置的绑定,具有了更高的泛化性,可以用来通道降维减少计算量,或通道升维增强模型表达力。
阅读建议
评论
匿名评论
隐私政策
你无需删除空行,直接评论以获取最佳展示效果